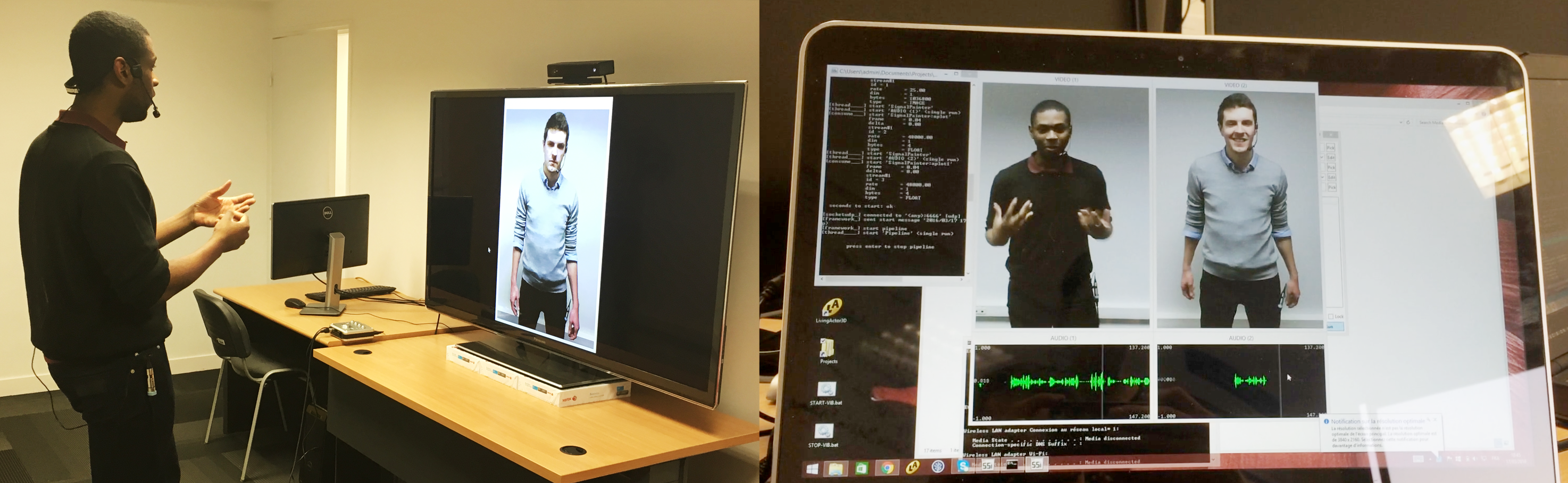
The Aria Valuspa Platform

The integrated Virtual Human framework will allow anyone to build their own Virtual Human Scenarios. Students are already using the framework to build a face recognition system that includes liveness detection, or to take questionnaires from people in a much more natural manner than asking people to fill in forms.The AVP comes with installation instructions, and a tutorial for running the default interaction scenario.The behaviour analysis component of the AVP comes with integrated Automatic Speech Recognition in English and German, valence and arousal detection from audio, 6 basic emotion recognition from video, face tracking, head-pose estimation, age, gender, and language estimation from audio.The default scenario of the dialogue manager presents Alice, the main character of the book ‘Alice’s Adventures in Wonderland’ by Lewis Caroll. You can ask her questions about herself, the book, and the author. You can of course also create your own scenarios, and we’ve created a tutorial with three different scenarios specifically aimed at getting new users started with this making their own systems.The behaviour generation components come with emotional TTS created by Cereproc, and visual behaviour generation using the GRETA system. It uses standard FML and BML, and features lip-synched utterances. The behaviour generation component has a unique feature that allows an ongoing animation to be stopped, thus allowing the agent to be interrupted by a user, which makes interactions with it much more natural.
The Novice-Expert Interaction (NoXi) Database
The idea behind NoXi was to obtain a dataset of natural interactions between human dyads in an expert-novice knowledge sharing context, with a number of controlled and induced interruptions of the interaction as experimental condition. The database is recorded in 3 main languages: English, French, and German, and has some recordings of 4 other languages. The expert participant was presumed to be knowledgeable about one or more topics that were of interest for both participants, whereas the novice was known to be willing to discuss and retrieve more information about that specific topic.In total, 89 people were recorded during 83 interactions. 32 recordings are in English, 21 in French, 19 in German, 4 in Spanish, 4 in Indonesian, 2 in Italian, and 2 in Arabic. A large diversity of topics was covered by our experts, including such diverse topics as expert computer science fields, various sports, history, magic tricks, tax systems, politics, and other trivia. In total 58 topics were discussed.The dataset includes sensor data from 2 Kinect 2.0s - RGB, depth data, and skeleton data, and audio. In addition audio was recorded from 2 close-talk microphones.The total duration of recordings is 22 hours and 25 minutes, and the total size of the database is approximately 4 TB.
The(non)verbal Annotator Tool (NOVA)
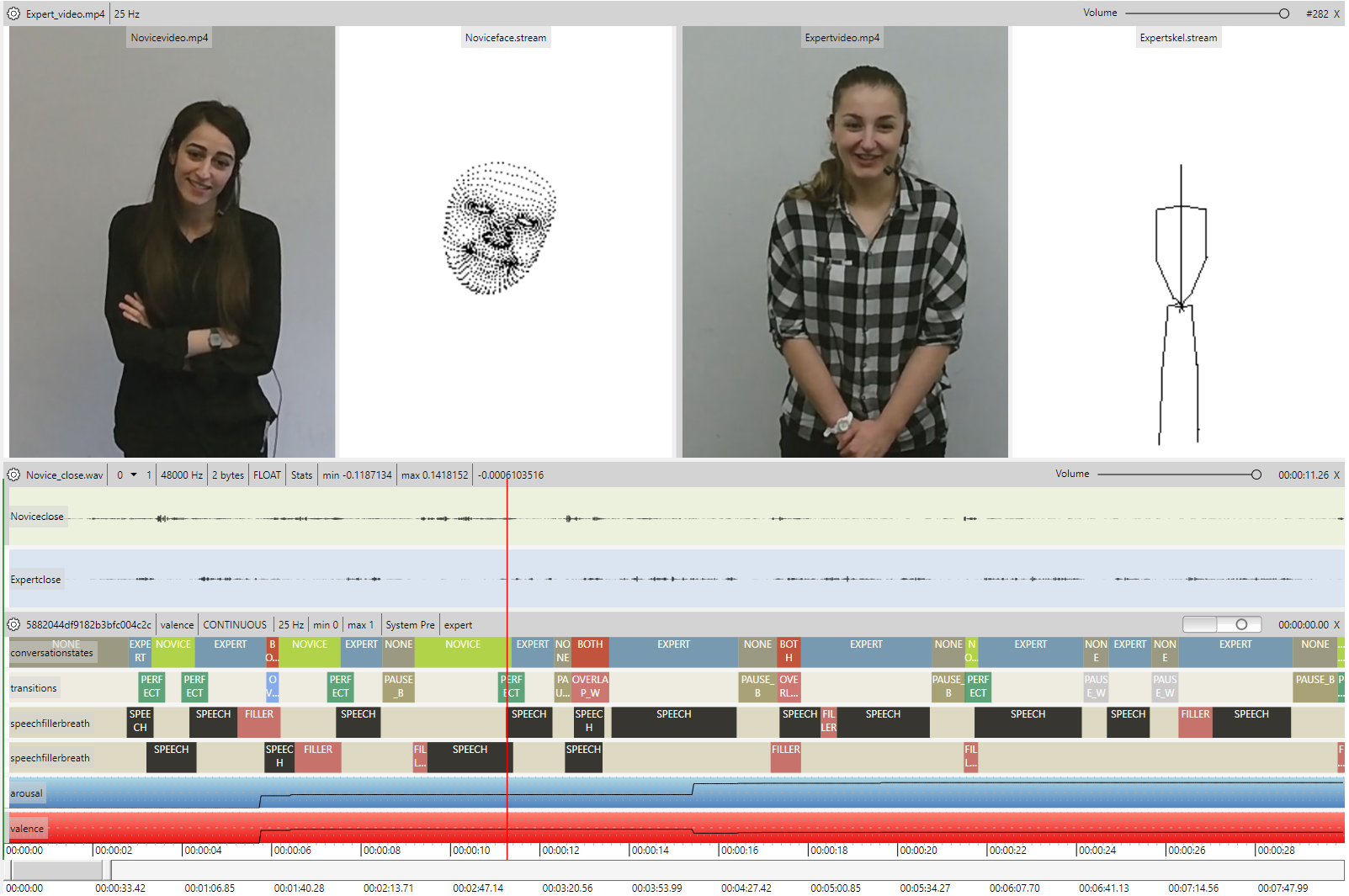
The NOVA user interface has been designed with a special focus on the annotation of long and continuous recordings involving multiple modalities and subjects. Unlike other annotation tools, the number of media files that can be displayed at the same is not limited and various types of signals (video, audio, facial features, skeleton, depth images, etc.) are supported. Further, multiple types of annotation schemes (discrete, continuous, transcriptions, geometric, etc.) can be selected to describe the visualised content. NOVA supports a database backend that allows institutes to share an easy to set-up annotation database to manage and share annotations. Several statistics are available to process the annotations created by multiple coders that can be applied to identify inter-rater agreement and annotations from multiple raters can be merged from the interface. NOVA further supports Cooperative Machine Learning tools to support an annotator already during the coding process with a Machine Learning Backend to speed up the annotation process.