
An important contribution of the ARIA-VALUSPA project is the NOXI database of mediated Novice-Expert interactions. It consists of 84 dyads recorded in 3 locations (Paris, Nottingham, and Augsburg) spoken in 7 languages (English, French, German, Spanish, Indonesian, Arabic and Italian). The aim of the endeavour is to collect data to study how humans exchange knowledge in a setting that is as close as possible to the intended human-agent setting of the project. Therefore, the interactions were mediated using large screens, cameras, and microphones. Expert/Novice pairs discussed 58 wildly different topics, and an initial analysis of these interactions has already led to a design for the flow of the dialogue between the user and the ARIAs. In addition to information exchange, the dataset was used to collect data to let our agents learn how to classify and deal with 7 different types of interruptions. In total we collected more than 50 hours of synchronized audio, video, and depth data. The NOXI database was recorded with the aim to be of wide use, beyond the direct goals and aims of the ARIA-VALUSPA project. For example, we have included recordings of depth information using a Kinect. While the project will not use depth information, other researchers will probably find this useful. The recording system has been implemented with the Social Signal Interpretation (SSI) framework. The database is hosted at https://noxi.aria-agent.eu/.
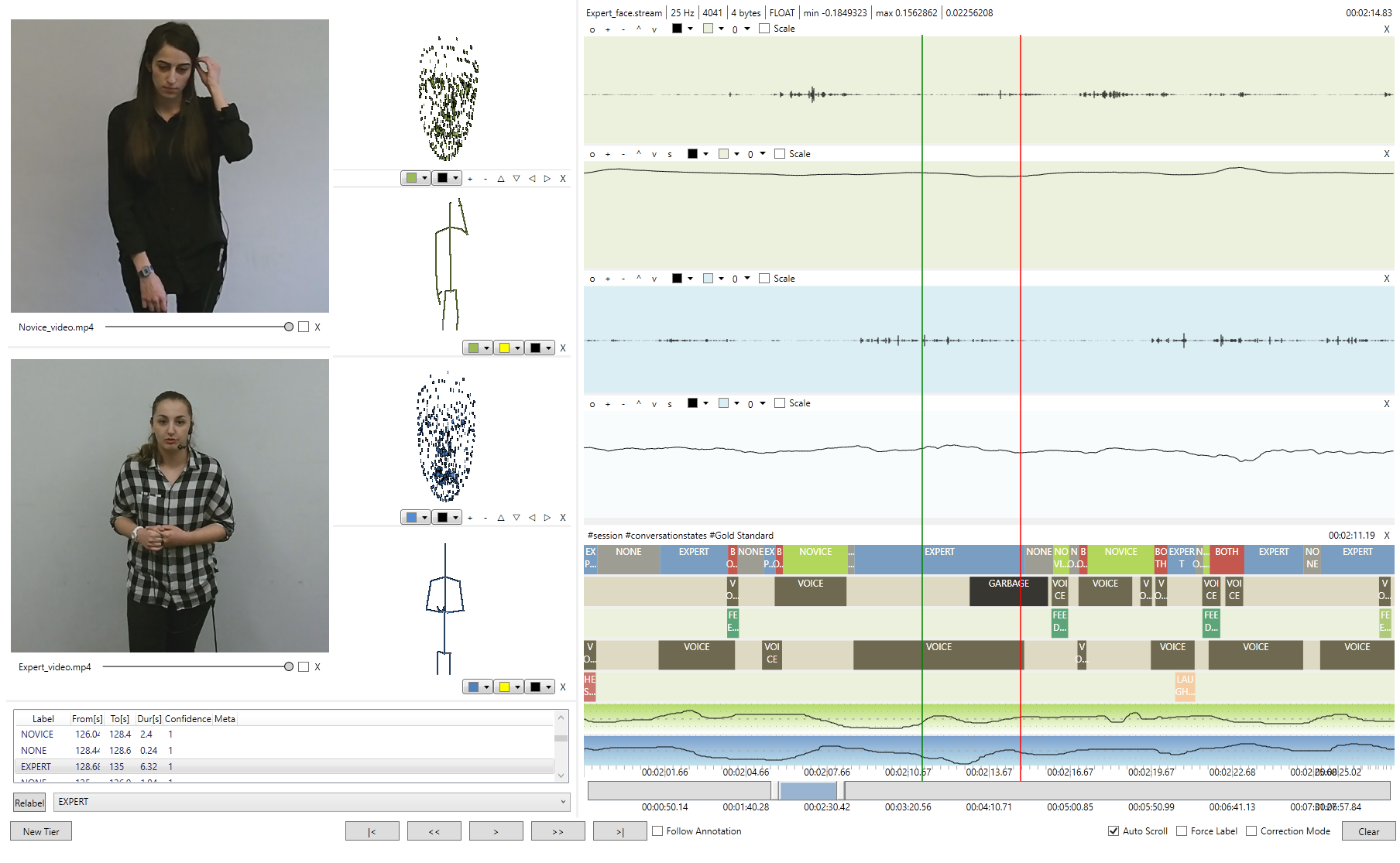
The value of a database highly depends on the availability of proper descriptions. Given the sheer volume of the data (> 50 h) a purely manual annotation is out of question. Hence, strategies are needed to speed up the coding process in an automated way. To this end, a novel annotation tool NOVA ((Non)verbal Annotator) is developed by the University of Augsburg. Conventional interfaces are usually limited to playback audio and video streams. Hence, a database like NOXI, which includes additional signals like skeleton and facial points, can be viewed in parts only. To visualize and describe arbitrary data streams recorded with SSI is an important feature of NOVA. The coding process of multimodal data depends on the phenomenon to describe. For example, we would prefer a discrete annotation scheme to label behaviour that can be classified into a set of categories (e.g. head nods and shakes), whereas variable dimensions like activation and evaluation are better handled on continuous tiers. For other tasks like language transcriptions, which may include hundreds of individual words, we want to be able to assign labels with free text. To meet the different needs, NOVA supports both discrete and continuous annotations types. Additionally, it includes a database backend to store recordings at a central server and share annotations between different sites. In the future, NOVA will be advanced with features to create collaborative annotations and to apply cooperative learning strategies out of the box.
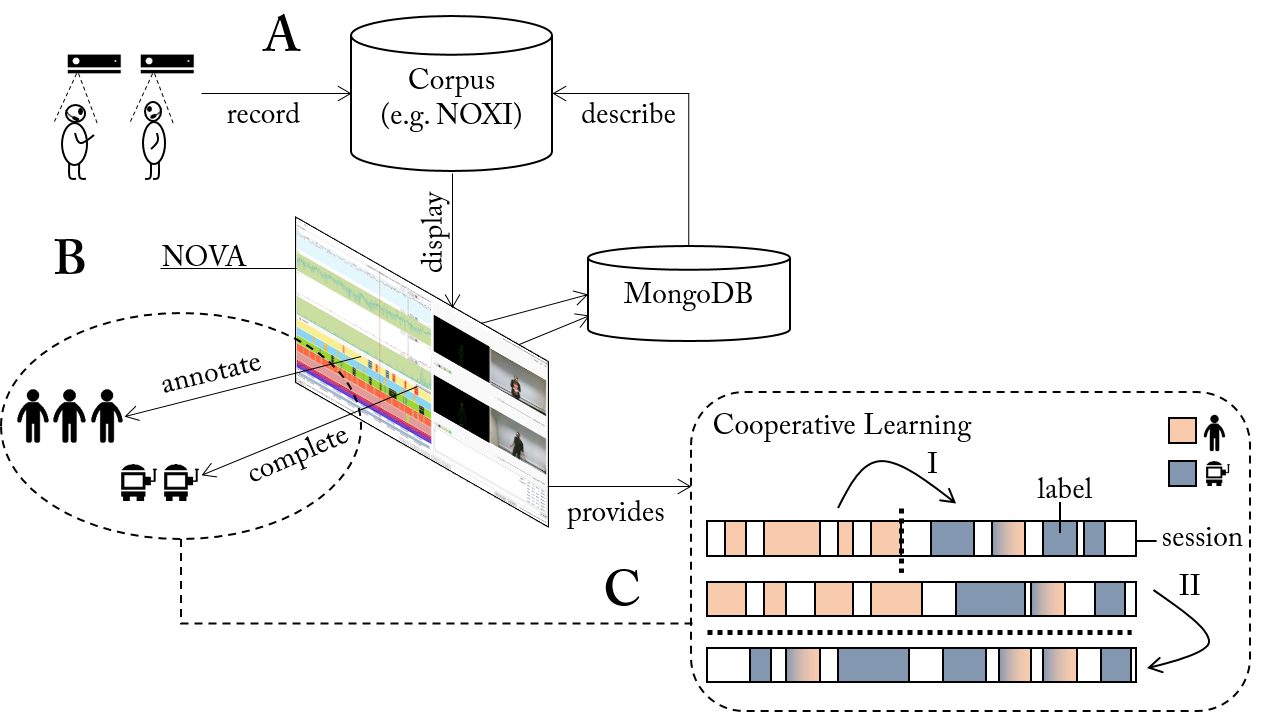
The above image gives an overview of the Cooperative Learning (CL) system that is currently developed in ARIA-VALUSPA and integrated into NOVA. (A) A database is populated with new recordings of human interaction (or alternatively from an existing source). (B) NOVA functions as interface to the data and sets up a MongoDB to distribute and accomplish annotation tasks among human annotators. (C) At times, Cooperative Learning (CL) can be applied to automatically complete unfinished fractions of the database. Here, we propose a two-fold strategy (bottom right box): (I) A session-dependent model is trained on a partly annotated session and applied to complete it. (II) A pool of annotated sessions is used to train a session-independent model and predict labels for the remaining sessions. In both cases, confidence values guide the revision of predicted segments (here marked with a colour gradient). To test the usefulness of the CL approach we have run experiments on the NOXI database, which show that labelling efforts can be significantly reduced that way. A joint publication is currently under review.