Congratulations to Elisabeth André

Award ceremony by Prof. Dr. Steve Feiner, Columbia University, New York, Chair, SIGCHI Achievement Awards Committee

Award ceremony by Prof. Dr. Steve Feiner, Columbia University, New York, Chair, SIGCHI Achievement Awards Committee

A team from CereProc supported by Dr Eduardo Manuel De Brito Lima Ferreira Coutinho
from the Imperial College demonstrated various aspects of speech synthesis at the Science Museum in London, as part of the Royal Society’s the Next Big Thing project.

Lates is a free event held once a month where adults take over the Science Museum. Every tevent has a different theme, covering a wide range of topics – from climate change to alcohol, from childhood to robots. These showcases have turned out to be extremely popular and attract around 5000 visitors per night.
Not surprisingly then, CereProc / ARIA team was kept busy all night. Our main activity was ‘Bot or Not’ – a quiz that lets you test your ability to recognize a synthetic voice and learn about speech synthesis in the process. Everyone who took part was added to the leader board and received a personalized message from Donald Trump (totally fake of course – generated using CereProc’s prototype Trump voice).
Feedback showed that most players found it a lot more difficult than they thought it would be – and no one has yet to reach the perfect score of 20/20!
Try it out here!
We also introduced visitors to (the voice of) Roger who gets very cross if you try to interrupt him while he’s speaking. The interruption demo was created for the ARIA – VALUSPA project as part of the effort to advance the conversational capabilities of virtual agents.
In addition, Dr Coutinho presented his work on sentiment analysis by demonstrating how to tell if a politician is being sincere when giving a speech. Once again, Mr Trump took a centre stage! Visitors also got a chance to record and analyse their own speech for signs of disingenuousness.
At CereProc, we live and breathe speech synthesis and we loved sharing our excitement with thousands of people who came along to the event. Like the Royal Society, we believe in promoting excellence in science and are proud to be part of the Next Big Thing movement!

The race to develop the best chatbot technology
It is no understatement to say that chatbots are generating a lot of interest from companies. All the big names in the IT industry (e.g. Google, Microsoft, Slack, IBM, Facebook, etc.) are following the trend and looking for new conversational interfaces.
Bots and artificial intelligence are broadening tech horizons. Development kits are now available to create artificial intelligence projects in a few clicks (see Skype, Facebook).
The increasing deployment of messaging applications – and conversational user interfaces – have truly boosted the growth of chatbots which today represent opportunities with few defined limits.
That said, imbuing more intelligence and “perceptual qualities” to these programs has become a major challenge.
Chatbots as meta-applications
Not only are chatbots outstanding gateways to the dissemination of relevant information, but they are also ideal for guiding users, segmenting information, and serving as true “hubs” capable of centralizing services. A chatbot is an e-concierge transformed into a virtual hub that manages applications that are too specialized, or too numerous!
A Nielsen analysis demonstrated that a Smartphone user clicks an average of 26 applications. According to another Gartner study, application usage tends to hit a plateau. Faced with a plethora of applications, a chatbot is a dream assistant—a service provider program that can be customized. What’s more, chatbots aren’t put off by learning! With a chatbot you can book a taxi, call a doctor, pay invoices, and more, all in the simplest and most natural way.
It’s no wonder that according to a study published by Oracle – “Can Virtual Experience Replace Reality?” – 80% of brands will use chatbots for customer interactions by 2020.
Are chatbots expressive and empathetic?
You and I don’t interact in the same way with human being or a chatbot. “Social” barriers aside, a chatbot will allow users to express themselves more candidly. The user often feel less “inhibited.”
Expressiveness can also be demonstrated in the choice of language programmed in a chatbot, and, if embodied by an avatar, in its facial expressions. The attitudes of this embodied chatbot will be able to “magnify a personality trait” or exaggerate emotions and reactions, in order to strengthen its message.
It is in this precise context that the “image and sound” become powerful. Text-based only formulas will be subject to misinterpretations. Combining text with an expressive avatar and/or voice will enrich the dialogue and strengthen the bond.
What if chatbots were granted a sixth sense?
We are not at the stage where chatbots can react as impulsively as humans, but nevertheless they are increasingly becoming more adaptive to the context of the situation.
Creating a chatbot with a wider analysis grid, a more comprehensive sensitivity spectrum, and adding other sensors to get it closer to being human is a real challenge. This is the focus chosen by the ARIA Valuspa project, whose idea is to develop the chatbot of tomorrow by offering more input channels, thus enabling it to better understand its user’s state of mind.
This more “sensitive” understanding will allow chatbots to personalize dialogues by adapting answers and reactions to the context. Chatbots will express their “emotions” with sentences, attitudes or voice and thus demonstrate a perfect understanding of the situation. They will synchronize, just like us!
Input signals are used to collect information including audio and video capture. These two sensors are able to detect several aspects related to one’s identity, stress level, and emotions experienced by the user. The dialogue can immediately become more personal and friendly.
These new chatbots are actually able to detect both verbal and nonverbal signals. They can identify the engagement of each of their users and thus adapt their pace or the amount of information they are sharing.
It is a real 6th sense that will complement current chatbots’ abilities. ARIA Valuspa’s virtual assistant offers multimodal, social interactions by assessing audio and video signals perceived as dialogue input. The aim of this project is to create a synthesizer “giving life” to an adaptive, intelligent chatbot, which is embodied by an expressive and vocalized 3D avatar.
The ultimate ambition? Establishing a real relationship based on trust with the user thanks to this new form of “virtual empathy.”


An important contribution of the ARIA-VALUSPA project is the NOXI database of mediated Novice-Expert interactions. It consists of 84 dyads recorded in 3 locations (Paris, Nottingham, and Augsburg) spoken in 7 languages (English, French, German, Spanish, Indonesian, Arabic and Italian). The aim of the endeavour is to collect data to study how humans exchange knowledge in a setting that is as close as possible to the intended human-agent setting of the project. Therefore, the interactions were mediated using large screens, cameras, and microphones. Expert/Novice pairs discussed 58 wildly different topics, and an initial analysis of these interactions has already led to a design for the flow of the dialogue between the user and the ARIAs. In addition to information exchange, the dataset was used to collect data to let our agents learn how to classify and deal with 7 different types of interruptions. In total we collected more than 50 hours of synchronized audio, video, and depth data. The NOXI database was recorded with the aim to be of wide use, beyond the direct goals and aims of the ARIA-VALUSPA project. For example, we have included recordings of depth information using a Kinect. While the project will not use depth information, other researchers will probably find this useful. The recording system has been implemented with the Social Signal Interpretation (SSI) framework. The database is hosted at https://noxi.aria-agent.eu/.
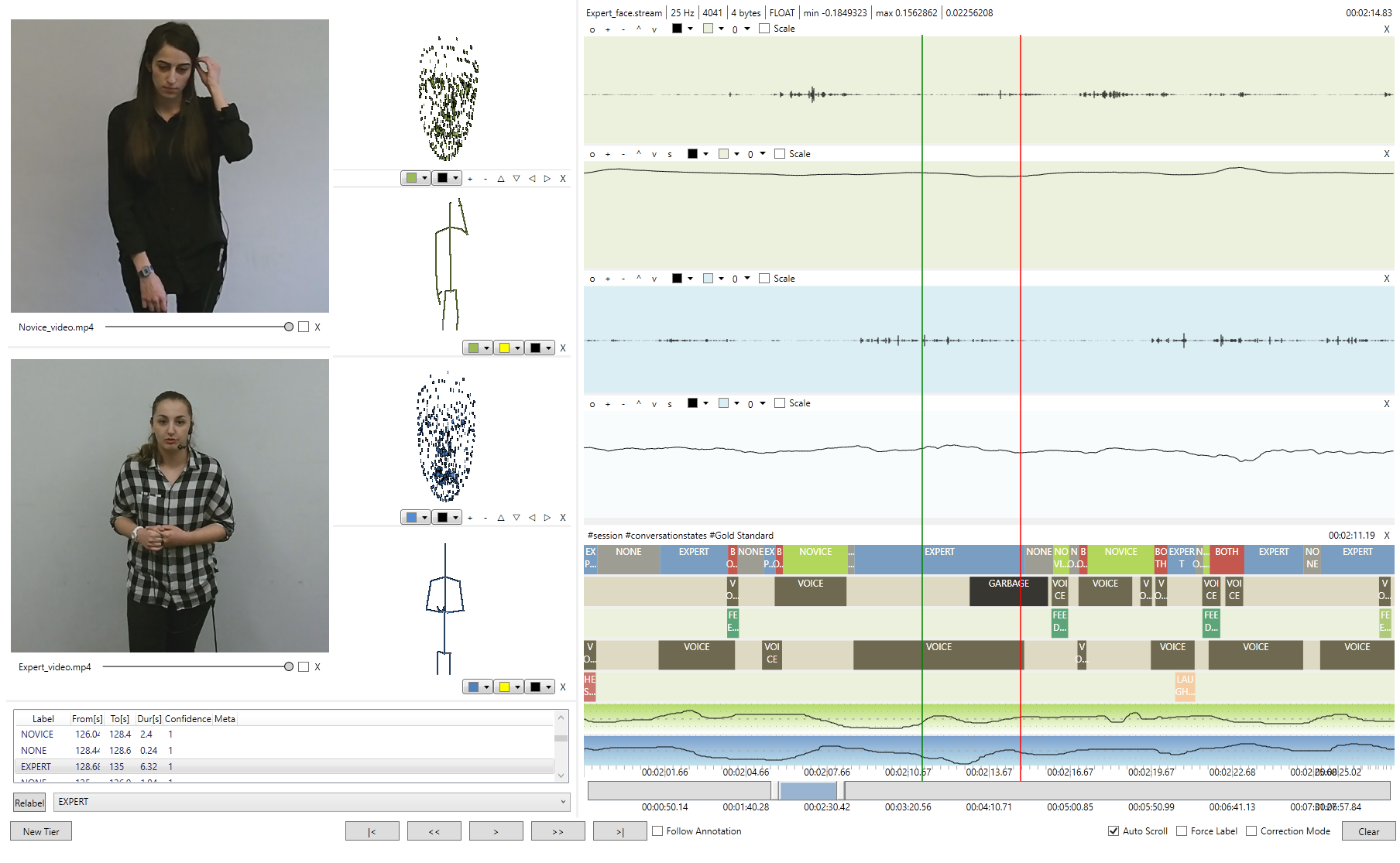
The value of a database highly depends on the availability of proper descriptions. Given the sheer volume of the data (> 50 h) a purely manual annotation is out of question. Hence, strategies are needed to speed up the coding process in an automated way. To this end, a novel annotation tool NOVA ((Non)verbal Annotator) is developed by the University of Augsburg. Conventional interfaces are usually limited to playback audio and video streams. Hence, a database like NOXI, which includes additional signals like skeleton and facial points, can be viewed in parts only. To visualize and describe arbitrary data streams recorded with SSI is an important feature of NOVA. The coding process of multimodal data depends on the phenomenon to describe. For example, we would prefer a discrete annotation scheme to label behaviour that can be classified into a set of categories (e.g. head nods and shakes), whereas variable dimensions like activation and evaluation are better handled on continuous tiers. For other tasks like language transcriptions, which may include hundreds of individual words, we want to be able to assign labels with free text. To meet the different needs, NOVA supports both discrete and continuous annotations types. Additionally, it includes a database backend to store recordings at a central server and share annotations between different sites. In the future, NOVA will be advanced with features to create collaborative annotations and to apply cooperative learning strategies out of the box.
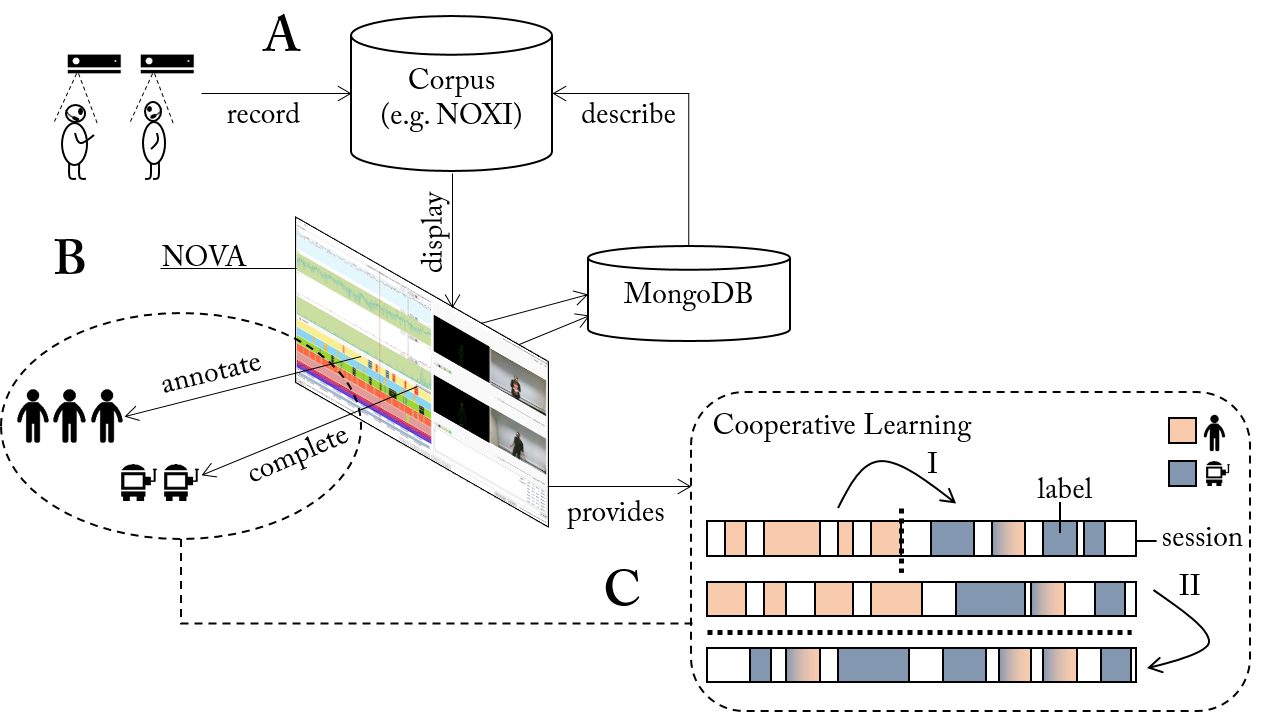
The above image gives an overview of the Cooperative Learning (CL) system that is currently developed in ARIA-VALUSPA and integrated into NOVA. (A) A database is populated with new recordings of human interaction (or alternatively from an existing source). (B) NOVA functions as interface to the data and sets up a MongoDB to distribute and accomplish annotation tasks among human annotators. (C) At times, Cooperative Learning (CL) can be applied to automatically complete unfinished fractions of the database. Here, we propose a two-fold strategy (bottom right box): (I) A session-dependent model is trained on a partly annotated session and applied to complete it. (II) A pool of annotated sessions is used to train a session-independent model and predict labels for the remaining sessions. In both cases, confidence values guide the revision of predicted segments (here marked with a colour gradient). To test the usefulness of the CL approach we have run experiments on the NOXI database, which show that labelling efforts can be significantly reduced that way. A joint publication is currently under review.



At the joint seminar at the Leibniz – Centre of Computer Sciences, Dagstuhl Castle, Wadern, the ARIA VALUSPA project met up with the EU project KRISTINA to exchange their insights, progress, promising approaches, and create new (research) friendships.
The Leibniz – Centre of Computer Sciences is located in the south-west of Germany and offers a very relaxed and secluded location where computer scientists can come together to discuss and work on their research.
The KRISTINA project aims to develop technologies for a human-like socially competent and communicative agent. It runs on mobile communication devices and serves for migrants with language and cultural barriers in the host country. The agent they develop will be a trusted information provision party and mediator in questions related to basic care and healthcare for migrants.

The two projects clearly owns many similarities, which allows both teams to learn from each other. However, during discussions they identified some interesting differences. The ARIA project is working on a natural interaction system, that focusses more on “social banter” such as real-time interruptions. These interruptions can be done by the user himself (the user starts talking when the agent is speaking) or by the agent (the agent starts talking when the user is speaking). By making the agent respond in an appropriate manner to interruptions, it is hoped for creating an atmosphere of a more natural “small talk”. The KRISTINA project is working on a task based system that relies more on information retrieval and transfer. A migrant can use their system to ask questions about their new home country, for example, how healthcare is organised.
During the joint seminar, both teams presented demonstrations of their systems. A notable demonstration of the ARIA project was done by Angelo Cafaro. He presented the handling by the virtual agent of user interruptions, which was realised on the behaviour generation level. For the KRISTINA project, Dominik Schiller presented the demonstration of how their agent could emphatically react to a depressed user. The ARIA VALUSPA team was very interested to understand how the KRISTINA system worked. Yet, the most impressive demo was held by Gerard (KRISTINA) and Angelo (ARIA VALUSPA), who managed to connect the Greta platform from the ARIA project to the agent web-interface from the KRISTINA project in about an hour. This emphasized the importance and effect of standards (i.e. FML and BML)!
Additionally, there was an interesting invited keynote by Patrick Gebhard from the DFKI lab, Saarbrücken. He detailed the work of the lab on the Virtual Scene Maker, which can be used for designing real time interactive systems. The demonstration of the system gave an insight on the impressive ease of the configuration possibilities in Virtual Scene Maker.

2017 started off well for the ARIA-VALUSPA project with the release of ARIA-VALUSPA Platform 2.0 (AVP 2.0), the second public release of the integrated behaviour analysis, dialogue management, and behaviour generation components developed as part of this EU Horizon 2020 project. The integrated Virtual Human framework will allow anyone to build their own Virtual Human Scenarios. Students are already using the framework to build a face recognition system that includes liveness detection, or to take questionnaires from people in a much more natural manner than asking people to fill in forms.
The AVP 2.0 can be downloaded from GitHub. It comes with installation instructions, and a tutorial for running the default interaction scenario.
The behaviour analysis component of the AVP 2.0 comes with integrated Automatic Speech Recognition in English, valence and arousal detection from audio, 6 basic emotion recognition from video, face tracking, head-pose estimation, age, gender, and language estimation from audio.
The default scenario of the dialogue manager presents Alice, the main character of the book ‘Alice’s Adventures in Wonderland’ by Lewis Caroll. You can ask her questions about herself, the book, and the author. You can of course also create your own scenarios, and we’ve created a tutorial with three different scenarios specifically aimed at getting new users started with this making their own systems.
The behaviour generation components come with emotional TTS created by Cereproc, and visual behaviour generation using the GRETA system. It uses standard FML and BML, and features lip-synched utterances. The behaviour generation component has a unique feature that allows an ongoing animation to be stopped, thus allowing the agent to be interrupted by a user, which makes interactions with it much more natural.
Another unique feature is the ability to record your interactions with the Virtual Humans. The framework stores raw audio and video, but also all predictions made by the analysis system (ASR, expressions, etc.), and in the near future it will also store all Dialogue Management and Behaviour Generation decisions, allowing you to replay the whole interaction. To simplify inspection and replay of an interaction, a seamless integration with the NoVa annotation tool is supported. NoVa is the new annotation tool developed as part of ARIA-VALUSPA to address shortcomings of existing multimedia annotation tools, as well as to provide integrated support for cooperative learning .
While the ARIA-VALUSPA Platform 2.0 presents a major step forwards in Virtual Human technology, we are always looking for ways to improve the system. Feature requests, bug reports, and any other suggestions can be logged through the GitHub issues tracker.
—————————————————————— Update ————————————————————————————
08. February 2017
A minor update to the ARIA-VALUSPA Platform for Virtual Humans has been released (AVP 2.1), containing mostly improved support for interruptions, logging of dialogue management actions, faster face tracking, and some bug fixes. Full release notes can be found here.
—————————————————————— Update ————————————————————————————
13. April 2017
An update to the ARIA-VALUSPA Platform for Virtual Humans has been released (AVP 2.2). Full release notes can be found here!

Catherine Pelachaud received the title Dr. Honoris Causa of the University of Geneva during Dies Academicus on October 14th 2016. The ceremony took place at the University of Geneva. The day before Catherine Pelachaud gave a seminar entitled “Interacting with socio-emotional embodied conversational agent” at the Faculty of Sciences.

“Ask Alice: An Artificial Retrieval of Information Agent”
The work of the ARIA-VALUSPA project was demonstrated on the 18th ACM International Conference on Multimodal Interaction – ICMI 2016 at Tokyo, Japan.




Human communication is rich, varied, and often ambiguous. This reflects the complexity and subjectivity of our lives. For thousands of years, art, music, drama and story telling have helped us understand, come to terms with, and express the complexities of our existential experience. Technology has long played a pivotal role in this artistic process, for example the role of optics in the development of perspective in painting and drawing, or the effect of film on story telling.
Information Technology has, and is having, an unprecedented impact both on our experience of life and our means of interpreting this experience. However the ability to harness this technology to help us understand, come to terms with, and mediate the explosion of electronic data, and electronic communication that now exists is generally limited to the mundane. Whereas the ability to get the height in metres of Everest is a trivial search request (8,848m by the way from a Google search), googling the question ‘What is love?’ returns (in the top four), two popular newspaper articles, a youtube video of Haddaway and a dating site. It is, of course, an unfair comparison. Google is not designed to offer responses to ambiguous questions with no definite answers. In contrast, traditional forms of art and artistic narrative have done so for centuries.
We might expect speech and language technology, dealing as it does with such a central form of human communication, to be at the forefront of applying technology to the interpretation of our ambiguous and multi-layered experience. In fact, much of the work in this area has avoided ambiguity and is often used as a tool to disambiguate information rather than as a means to interpret ambiguity. Take, for example, conversational agents (CAs): These are computer programs which allow you to speak to a device and will respond to you using computer generated speech. These systems can potentially harness the nuances of language and the ambiguity of emotional expression. However, in reality, we use them to ask them how high Everest is or where you can find a nearby pizza restaurant. Although the ability to deal with these requests is important if you are writing an assignment about Everest, or wanting to eat pizza, it raises the question of how we might extend such systems to help us interpret more complex aspects of the world around us. It is important for this technology to strive to do so for two fundamental reasons: firstly, technology has become part of our social life and as such this technology needs to be able to engender playfulness, and enrich our sense of experience, and secondly, applications which could perform a key role in mediating technology for social good require a means of interacting with users in much more complex social and cultural situations.
Conversation has a tradition as a pass time, as means of humour, as a means of helping people with their problems. However, the scope for artificial conversational agents to perform these activities is currently severely limited. In ARIA-VALUSPA we explore approaches that give conversational agents more subtle means of communicating, of becoming more playful, and representing the ambiguity in our social experience.
The technology required to do this requires close collaboration with engineers working on dialogue. CereProc Ltd, a key partner in ARIA-VALUSPA, is very active in developing techniques to make artificial voices (termed speech synthesis or text-to-speech synthesis, TTS) more emotional, expressive and characterful. These techniques include changing voice quality – for example making a voice sound stressed or calm – adding vocal gestures likes sighs and laughs,changing the emphasis from one word to another to alter the subtle meaning in a sentence, changing the rate of speech and the intonation to change how active the voice sounds, and even just making sure the voice doesn’t always say the word ‘yes’ the same way every time it
says it.
This key work on the way speech is produced can then be used to alter the perceived character of a conversational agent, or convey an internal state.
So perhaps, in the future when we ask a system ‘What is Love?’, perhaps its wistful voice will hint at past romance lost, the sense of longing for a human connection, and help us find answers which are not fixed, but emotional and depend on the different experiences we share as human beings.